
有经验的法律从业人员大致都会认同这个论述:法律判断是一个事实发现、事实还原、事实认定、与法律适用的边界划定的过程。
在非案例法国家里,这个论述可能更为贴近裁判的原型,在案例法国家法官和律师被训练从一个案例到另一个案例进行类推的论证,在非案例法国家,法官和律师会更频繁的尝试从成文法法律渊源中做出各种类推的解释,以对个案的事实进行A法律关系或者B法律关系的厘定,我在这里称为“边界划定”。无论是案例法国家还是非案例法国家,类推与解释都是法律人最典型的思维方式。
而若给定事实,这个边界划定依靠的说理,本质上就是一种语义的缩放过程(文义解释、上下文解释、历史解释、扩张解释、缩小解释等),而语义的缩放、扩散、联想正是生成式人工智能(LLM)的一个明显强项。
LLM的训练过程就是海量人类语言数据输入后,从一个词之后的下一个词概率性来学习的,这个技术的工作方式是,将单个词语转化为代表词语之间关联的数字,有点像一个“词云”。 它能够确刃像”责任”和”损害”这样的词语似乎是明显相关的,因为它会注意到在数千个示例文档中,这些词语会被紧密地使用在一起。这种学习方式很显然的,借鉴了类推这一法律人思维方式。
备忘录写作:法律数据库综述
把一些特定法律问题的信息(例如备忘录、类似文章、同案由案例等)做成数据库,让LLM阅读,之后向他提问,形成新的语义综述。例如,现在可以用google workspace和Github,并在上面调用GPT的API形成代码,可以部分解决这个问题,创立一个自己的小型数据库。举例而言,对于特定的情况,我想写作一篇法律备忘录,关于如何利用中国著作权法第二十二条规定的“合理使用”例外使用著作权人作品,那么将类似的20篇公开资料、学者文章输入GPT,之后通过提问、人工交互与微调形成一篇自己的备忘录,应用于独特的事实场景。
类推与心证:人工法官与机器法官的分工
目前GPT4的训练截至2023,而且主要以英文为主,那么,如果我们继续第一部分的数据库输入方法,提供一个非常庞大的中文法律数据库并着重于说理部分的信息输入,则GPT或者其他中国本土生成式人工智能将给出更多的法律说理部分。
以下作者尝试猜想、阐释并模拟这个过程。
不考虑判决的政治因素,中国法实践下,民事诉讼法与刑事诉讼法给与法官的自由裁量权主要是在关于事实的证据部分,自由心证主要依靠法官的主观意识与经验知识来对事实“碎片”进行必要的挑选与组合以最终确定纠纷事实的过程。那么,如果我们通过GPT或者其他中国本土生成式人工智能,在输入海量司法数据(包括但不限于法律法规、类案判决、裁决、内卷、法官会议纪要、庭委会记录、审委会、笔录等)后,形成了一个机器法官(助理)的角色,那么人工法官与机器法官未来将可能怎样合作进行事实认定与法律认定呢?
作者认为,审判过程中,人工法官分工上会更着重用事实发现,机器法官仍旧是一个使用数据库的概率机器,而人工法官要做道德判断,道德判断首先是对事实判断,其次是对机器法官输出的论证的法律判断,即首先验证机器法官的判断,之后改正机器法官的判断。[1]
机器法官输出的是法律适用的说理部分,尽管机器法官的法律说理的来源,或者说思考方式,不是经过多年法学教育的人工法官或者人工律师的法律理解逻辑,而是前文所说的语义之间的联系,但通过这种方式训练的机器仍可以会制造出不同类型的逻辑自洽的法律说理,典型的事例是微软公布的Chatgpt4 在美国律考的客观题部分得分明显比主观题部分高,但主观题部分的得分4.2/6,仍然高于多州划定的通过率4/6[2]。
人工法官更准确的说会把事实确认后输入,或者按概率确认不同事实的真假概率后输入机器法官,机器法官根据数据库给出一个或者好几个可能的法律论证,而鉴于主观论证部分的缺陷,以及数据库中的错误将相比传统的人工论证起草过程对判决结果造成更大的损害[3],最后一定是交由人工法官对法律问题进行选择是否采纳、是否微调。
可以同时想见,在拥有类似经过数据库训练的机器后,律师也会采用类似的方法来选择自己的证明路径。一个可以想见的结果是,大量的有法律争议的案件将会被更充分的进行论述,这最终会对现在的法院与仲裁审理结构造成什么影响,我们可能还无法预测,但基于上述分析的几个可能猜想是:
- 对事实和证据的考察将会更加精细;律师、法官、仲裁员之间的人类交互行为将更重要的成为判断事实和证据的依据,这种人类交互行为可能包括更细微的表情、心理特征显露等。
- 因训练逻辑的不同等原因,最终判决裁决的法律判断(legal judgement) 还是会交到人工手上。
- 案例法国家常用的类推和类推的各种限制规则的产生、发展和应用,可能亦会成为非案例法国家人工法官和人工律师最终进行法律判断的重要依据,尽管这种依据不会成为法律依据,但人工法官和人工律师会更偏向于用这种方式思考,来对机器的论述加以甄别。
海量数据下对类案证据认定的概率可能对法官心证产生影响
机器法官依照数据库,通过被提出适当的问题,反过来会对人工法官事实的发现和证据心证产生制约和影响。
目前我们司法实践中,法官一般会参考其他案例,这些案例都是个别挑选过的案例,反映了诉讼各方不同的诉求。但通过使用根据类案数据库,人工法官可以对较难认定的事实问题对机器法官进行提问,通过被提出适当的问题,机器法官可以选择用百分比的概率回答事实性问题的可能性,而这种百分比其实对于法官的心证而言相对个别案例更直观有冲击力。
试举一例
民间借贷案件中,各种证据是否可以确认一个事实,用以证明原告提出的“无借条、纯现金支付”的借贷关系随着现金交付而成立?这里的核心是是否交付现金, 传统裁判者一般依靠各种证据进行心证判断,而如果把类似问题提供给机器法官,则机器法官可以通过数据库快速告知类似案件认定交付的概率以及认定证据不足的概率。
若把这种类案的认定事实概率与个案的事实认定心证概率,即民诉法意义上的盖然性(51%-74%)、或高度盖然性(74%-99%)的心证进行对比,则会产生更多值得思考的问题。
SORA的出现
本文主体内容写作于2023年年底,2024春节后出现的引起轰动的SORA导致媒体广告行业出现恐慌情绪,很多其他职业,包括法律行业从业人士也会有类似的恐慌心理。这里表达一下作者的观点。
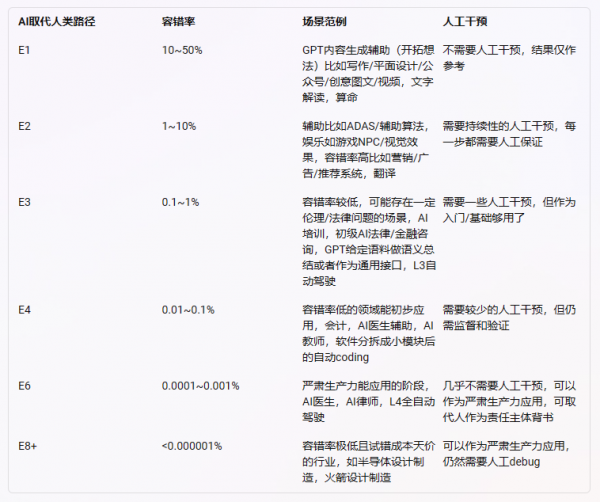
如前文所述,法律与医疗之类严肃领域责任主体是个绕不过去的问题,而法律领域还有一个判断主体的问题,即制度上必须由法官进行价值判断,而这个价值判断在一定真值范围内(清晰与模糊的事实范围内)无所谓对错,也正是因此,我们在上文中模拟了未来更低容错率下,机器法官与人工法官的工作划分。
作者认为,GPT4的惊艳推理能力涌现后,和人类的区别仍在于特定领域内每一步的出错概率。鉴于生成式人工智能(LLM)的原理[4],往前推理的越多,每一步出错的概率相乘,最后结果的准确率会产生指数级别的下降(不考虑未来AGI出现的情况)。除非未来LLM产生了很强的self-debugging的能力(类似于人类专业人士 判断+验证+改正)。
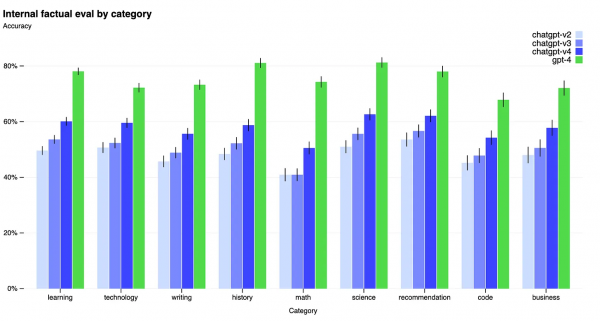
上图源于Open-ai白皮书,GPT4现在的容错率大约是20%。
SORA的出现,是直接降低了每个人把对文字的想象力变成视频画面的成本。而随着容错率的提升,人工智能会由高到低的行业开始“取代”人类,SORA的冲击也来源于娱乐方面的直觉感觉,让视频行业从业人员有了更先进的装备,类似于前文所说的,类比娱乐行业人员有了一个免费、巨大、并可以对事实问题和法律问题进行直接并准确判断的“法律数据库” 。
结语
对于法律职业而言GPT等生成式人工智能工具非常适合在知识丰富的法官、仲裁员、律师的监督下处理法律任务。法律是一个文字的职业,而生成式人工智能在这方面表现得非常出色。通过本文论述,可以想见,未来法律文本的生成速度、质量将大大提高,未来法律SORA的出现,可以将诸多矛盾的价值判断快速的在案例库中找到核心论据与依据,这种快速发现事实与法律的能力,虽然无法替代庭审环境下的人工再判断,但必将对法律实践带来许多改变。
(本文仅代表作者个人思考与观点,错误难免请多多指正。)
[1] 法官、律师、医生这类职业,出现重大责任需要自然人作为责任主体,容错率非常非常低,甚至因为制度要求,必然出现的错误也必须经过正当程序才能得到合理化。法律人更区别于医生,法律(特别是诉讼领域)需要人进行主观价值判断,并且是通过律师与法官的交互行为“发现”事实与价值判断,容错率既低(基于事实),又高(基于法律),那么主观价值判断必然来源于人。
[2] See: https://www.abajournal.com/web/article/latest-version-of-chatgpt-aces-the-bar-exam-with-score-in-90th-percentile
[3] 在传统的人工法律论证过程中,词语的选择更为谨慎,事实的检查更为彻底。
[4] 大语言模型需要预测下一个词出现的概率,每一个输出词都是根据已经产生的输出词进行填空,目标函数需要最大化输出的概率,那么每个词输出时就必要几率会出错。那么大语言模型本质就是一个统计推断。